p-token: How Solana Rewrote Its Most Important Program
Sourav Mishra
May 28, 2026 • 21 min read



TL;DR: The SPL Token program is the most-used piece of code on Solana. Nearly every non-vote transaction touches it, and it was quietly burning about 10% of every block's compute. So Anza rewrote it from scratch in a zero-dependency framework called Pinocchio and got a token transfer down from 4,645 compute units to 76. Then came the scary part: they swapped the new code in at the same address the old program lived at, behind a feature gate, at an epoch boundary, while billions of dollars sat in accounts that point to it. This is p-token (SIMD-0266). It's byte-for-byte compatible, so your client code didn't change a line. It went live on mainnet in spring 2026, and most people never noticed. That was the whole idea. Below: what happened under the hood, why a transfer got 60x cheaper, how you replace the most important program on a $100B+ network while it's running, and the one thing that did change for anyone reading token data off the chain.
There's a program on Solana that your code calls more than any other, whether you wrote that call or not. Every USDC transfer. Every swap leg. Every memecoin mint, every NFT that's really an SPL token, every "wrap SOL" in a Jupiter route. It's the SPL Token program. It lives at TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA, and for years it was one of the least efficient things on the network, for a simple reason: nobody thought about it. It just worked, so it never got touched.
Then someone added it up. Token instructions were eating roughly 10% of the compute units in every block. Not 10% of token-related blocks. 10% of all blockspace, everywhere, all the time, for a program whose job is mostly "subtract here, add there."
So Anza rewrote it. The new version is called p-token. It does the exact same thing as the old one, byte-for-byte, for a fraction of the compute. Then they replaced the old program in place: same address, same accounts, live on mainnet. Almost nobody noticed. That last part is the one worth understanding.
The Most Expensive Cheap Thing on Solana
Compute units are the scarce resource on Solana. Not money, not storage. Compute. Every block has a hard cap, currently 60M CU, with a 12M budget per account write lock. Every instruction draws from that cap. When blocks fill up, your transaction's priority comes down to fee per compute unit. CU is the currency that actually rations blockspace.
Against that backdrop, look at what the old SPL Token program charged for the single most common operation on the network:
- A plain
Transfer: 4,645 CU - A
TransferChecked: 6,200 CU
That sounds small until you remember how often it runs. Transfer and TransferChecked together are nearly half of all token-program activity, and the token program is ~10% of all blockspace. So you're paying that 4,645 on a huge number of transactions every day, and a big chunk of it isn't doing anything useful. Some of it was pure logging: before a single lamport moved, the program would write Program log: Instruction: Transfer to the transaction log, and that one line burned around 103 CU.
The waste wasn't in the logic. The logic of a token transfer is trivial. The waste was in everything wrapped around it: how the program received its accounts, how it parsed them, and how much machinery the standard Solana program model dragged in before the first useful line ran. p-token's whole idea is that you can keep the logic identical and throw away the wrapping.
Here's what "throw away the wrapping" actually bought, per instruction:
| Instruction | p-token | old SPL Token | Saving |
|---|---|---|---|
transfer |
76 | 4,645 | ~98% |
transfer_checked |
105 | 6,200 | ~98% |
initialize_mint |
105 | 2,967 | ~96% |
initialize_account |
154 | 4,527 | ~97% |
mint_to |
119 | 4,538 | ~97% |
burn |
126 | 4,753 | ~97% |
approve |
124 | 2,904 | ~96% |
close_account |
120 | 2,916 | ~96% |
freeze_account |
146 | 4,265 | ~97% |
sync_native |
61 | 3,045 | ~98% |
(Benchmark figures from the official p-token upgrade page and SIMD-0266. Exact counts drift a few units between Solana releases and benchmark runs, but the shape doesn't.)
That's the whole pitch in one table. Same instruction set, same account layouts, same results, for 95-98% less compute. On a plain transfer, the operation Solana runs most, that's 4,645 CU down to 76: about 60x cheaper.
What p-token Actually Is
First, kill the most common misconception: p-token isn't a new token spec, isn't a Token-2022 successor, and isn't something you migrate to. It's a from-scratch reimplementation of the existing SPL Token program, compatible byte-for-byte: same instruction discriminators, same account layouts, same error codes, same everything an outside observer can see. Hand it the bytes for an InitializeMint instruction and it reads them the same way, writes the same account state, and returns the same errors as the program it replaces.
The "p" is for Pinocchio, the framework it's built on. Pinocchio is where the savings come from.
Pinocchio began as a personal experiment by Fernando "Febo" Otero, an engineer at Anza, aimed at one specific frustration: the solana-program crate historically dragged in a heavy, constantly churning dependency tree, and he wanted out. The experiment caught on inside Anza and absorbed enough of the team to become a real project, and a genuinely different way to write a Solana program. Its tagline is "Create Solana programs with no external dependencies attached," and it means that literally. It's no_std, it has zero external crates, it lets you drop the heap allocator entirely, and it never copies your accounts into owned memory. It's a solana-program replacement built for two things: minimum compute and minimum binary size.
p-token, the rewrite of SPL Token on top of Pinocchio, was the proof. It shrank the program binary from 131 KB to 95 KB and cut compute by ~95%. Febo and Jon Cinque wrote it up as SIMD-0266: Efficient Token Program, and that proposal is what carried it to mainnet.
Where the Compute Actually Went
This part is useful even if you never touch p-token, because it explains why a normal Solana program costs more than its logic suggests.
When the Solana runtime invokes your program, it hands over one thing: a pointer to a serialized byte buffer. That buffer holds the program ID, the accounts, and the instruction data, all packed into a specific layout. What your program does with it next is where frameworks split apart.
The standard solana-program entrypoint, the one almost every program uses, does the friendly thing. Before a single line of your logic runs, its deserialize routine walks that buffer and builds owned Rust structures. It allocates a Vec<AccountInfo> on the heap, and for every account it wraps the lamports and data in Rc<RefCell<…>>, reference-counted smart pointers you can mutate through. That's convenient. It's also a pile of allocations and copies on every single invocation, and it grows with the number of accounts. You pay for it whether or not your program touches those accounts. It even sets up a heap allocator and a panic handler you may never use.
Pinocchio refuses to do almost all of that.
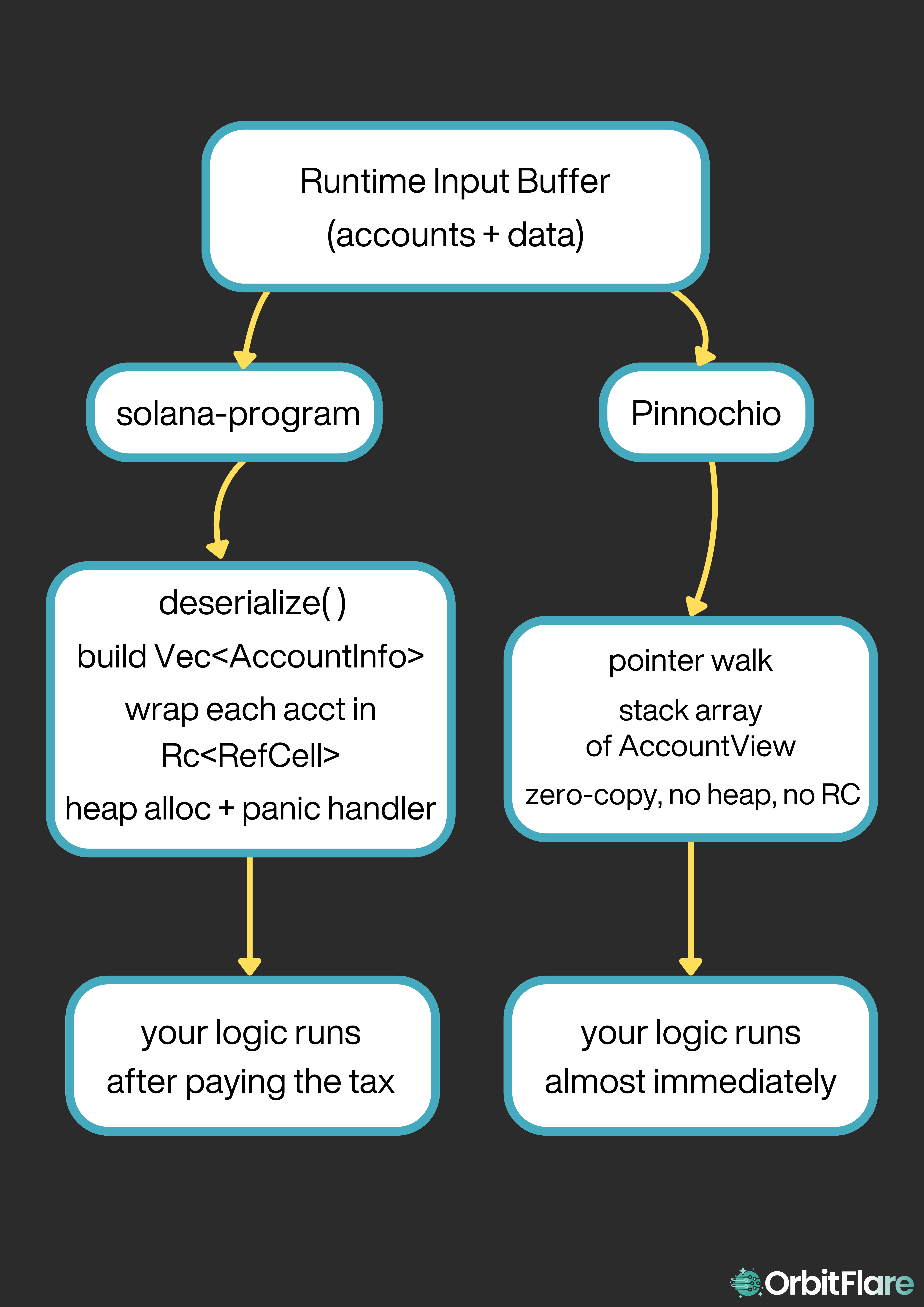
Pinocchio's account type is basically a typed pointer into the runtime's input buffer. It doesn't copy the account data anywhere. It reads lamports, owner, and data in place, through the pointer. That's what "zero-copy" means here. Instead of a heap Vec, it writes those pointer-views into a fixed-size array on the stack. No Rc, no RefCell, no allocator, no std. With one macro you can forbid heap allocation entirely, so the compiler guarantees your program never touches the heap.
Most of the compute reduction came from two changes: replacing the standard entrypoint and switching to zero-copy account access. The rest came from dropping solana-program, hand-writing the instruction dispatch, and removing the per-instruction log line. (Remember, that log line alone cost ~103 CU, pure overhead just to print the instruction's name.)
The tradeoff is real, and worth saying plainly: Pinocchio is much more manual. No automatic account validation, no account model, no IDL generation, more unsafe, more pointer arithmetic, more ways to shoot yourself in the foot. Anchor hands you guardrails. Pinocchio hands you the bare runtime and trusts you to check signers, ownership, and writability yourself. For a tiny, frozen-spec program like SPL Token, which gets audited to death and almost never changes, that's a fine bargain. For your app, it usually isn't. If you want a middle ground, Steel keeps zero-copy parsing but adds back some ergonomics. At the far extreme, there's hand-written sBPF assembly. Pinocchio sits close to that assembly end.
Three Things It Can Do That the Old One Couldn't
Byte-for-byte compatibility means p-token can't remove behavior. But it can add. SIMD-0266 ships three new instructions, all purely additive.
batch (discriminator 255). This is the sleeper. A cross-program invocation has a fixed cost of roughly 1,000 CU just to make the call, before the called instruction does anything. A program that does several token operations in one transaction pays that ~1,000 CU every time. Think of an AMM handling a deposit: transfer A, transfer B, mint LP. Three calls, three times the entry cost. batch lets you bundle multiple token instructions into a single invocation, so you pay the CPI entry cost once for the whole batch instead of once per instruction.
withdraw_excess_lamports (discriminator 38). Over the years, people have accidentally sent plain SOL straight to mint and multisig accounts, where it just sits above the rent-exempt minimum with no way out. The total isn't small: something like 177,000 SOL, tens of millions of dollars, stuck in token mint accounts. This instruction lets the proper authority sweep that excess back out. (Discriminator 38 deliberately matches Token-2022's existing equivalent.)
unwrap_lamports (discriminator 45). A cleaner path for native (wrapped) SOL. You move lamports straight out of a native token account to a destination, skipping the old dance of creating and closing a temporary account.
Swapping the Engine While the Plane Is Flying
Now for the audacious part.
You have a program at Tokenkeg…VQ5DA. Hundreds of billions of dollars of token accounts name it as their owner. Thousands of other programs call into it by that address. And its upgrade authority was burned long ago, so for all practical purposes it's immutable. You can't just send an upgrade transaction. So how do you replace its code without asking the whole ecosystem to migrate to a new address? Migrating was explicitly rejected, because adoption would crawl and most of the benefit would evaporate.
You do it at the runtime level, behind a feature gate, and you let consensus perform the swap atomically. Here's how it goes:
- Pre-deploy the verified bytecode to a separate staging address:
ptok6rngomXrDbWf5v5Mkmu5CEbB51hzSCPDoj9DrvF. This is just a holding pen. The audited code sits on-chain, where anyone can inspect it, before anything changes. That "ptok…" address is the source, not the destination. - Ship the change behind a feature gate (
ptokFjwyJtrwCa9Kgo9xoDS59V4QccBGEaRFnRPnSdP) inside a new validator release. Operators upgrade their software, but nothing actually switches yet. - Vote. Because this carries enormous economic weight, SIMD-0266 went to a stake-weighted validator vote and needed the standard supermajority of participating stake. It passed in early 2026.
- Activate at an epoch boundary. Once enough stake is running the new code, the feature gate flips. Every validator's runtime, in lockstep, replaces the executable at
Tokenkeg…VQ5DAwith the bytecode from the staging address, through the Upgradeable BPF Loader. The address keeps its identity. Only the code behind it changes.
The swap doesn't go through the normal upgrade path, so the frozen upgrade authority never gets in the way. The validators just agree to run the new code at the next epoch boundary. p-token went live on Solana mainnet in spring 2026, at epoch 971. To stay in sync, validators needed Agave v3.1.7+ or Firedancer v0.812.30108+. Devnet had switched over earlier. For almost everyone (users, wallets, and other programs), the only thing they noticed was that token transactions got cheaper. Nothing to update, nothing to migrate.
Rewriting the Crown Jewels Without Losing Them
Here's the question that should make any serious engineer nervous. You just rewrote, from scratch, in a framework that leans heavily on unsafe and raw pointers, the single program that holds the largest share of value on Solana. Then you atomically replaced the old one with it. A subtle bug here isn't a worse user experience. It's the backbone of every DeFi position on the network behaving differently than the code that secured it yesterday. How do you ever get comfortable with that?
The answer is one of the more interesting safety-engineering stories in recent Solana history, and it's worth knowing, because it isn't "we audited it and hoped."
Differential testing against real history (Neodyme). This is the strongest pillar. Neodyme built a harness in their Riverguard fuzzer that replayed essentially every mainnet transaction that ever touched the token program through both programs, old and p-token, and diffed the results. The question wasn't "do the tests pass." It was "given the actual transactions that really happened on Solana over months, does the new program produce byte-identical account state, the same metadata, and the same error codes, in the same priority order, as the old one?" After months of running: not a single divergence. The same harness measured the payoff. Over one sample window (Aug 3-11, 2025), p-token would have saved 8.9-9.1 trillion compute units, about 12% of the entire chain's blockspace, vote transactions and all. That 12% is the honest, auditor-measured number to anchor on, more so than the per-instruction headline percentages.
Independent audits that actually found things (Zellic). Zellic audited both Pinocchio and p-token and surfaced 8 findings, one Critical and three High. Among them: an out-of-bounds read in a memory-copy helper (copy_val) caused by a loose generic bound, plus several memory-safety traps from the heavy use of unsafe and MaybeUninit. All were fixed.
The bug that proves the point (Asymmetric Research). Before mainnet, Asymmetric Research found a real loss-of-funds bug. Tellingly, it lived in the new functionality, not the replicated logic. As an optimization, p-token defers some ownership checks to the runtime's end-of-transaction validation. The new batch instruction runs multiple state transitions in one invocation. Combine the two and you could craft a fake native-token account, bump a victim's wrapped-SOL balance with no real lamports to back it, then restore the fake account's bytes before the runtime's ownership check ran. The tampering was invisible to validation. The fix was to add explicit ownership checks to batch.
Formal verification (Runtime Verification) rounds out the stack as a third independent leg. Alongside it sit Anza's own differential fuzzer, which by Neodyme's account had already caught everything Neodyme later flagged, and Firedancer's fuzzing tools.
Stack it all up, and the case for trusting p-token isn't "trust us." It's a hard, narrow spec: be byte-identical to a program we've run for years. That spec got checked against real chain history at scale. Multiple independent teams attacked it and found real bugs, which got fixed. Formal proofs went on top. And the whole thing rolled out behind a vote and a feature gate, so it only switched on once the network agreed. The leftover risk isn't zero. It never is. But it was driven down about as carefully as a change like this can be.
What Actually Changes for You
For most people building on Solana, the honest answer is nothing. Your client code keeps working, because the instruction and account layouts are identical. Your transfers just got cheaper. Done.
But there are two groups who should pay attention, and because you're reading an OrbitFlare post you're probably in one of them.
If you index or stream token activity, the logs changed. Remember that ~103 CU log line p-token deleted? A lot of indexers identified token instructions by scraping exactly that text, matching on Program log: Instruction: Transfer to label what happened. p-token doesn't emit it. If your pipeline leans on log strings to classify token instructions, it goes blind on the new program. The fix is the thing you should have been doing anyway: decode the instruction data against the IDL instead of reading prose out of logs. The updated IDL ships in the solana-program/token repo, with refreshed clients (@solana-program/token and spl-token-client) that expose the new instructions. This is the one concrete migration the upgrade forces, and it lands on data infrastructure, not on apps. If you consume a stream that already hands you decoded, structured transactions, this was a non-event. If you built your own log-scraping layer, this is your cue to retire it.
If you trade, the priority math shifted. Priority is fee per compute unit. A token-heavy transaction that now burns a fraction of the CU it used to can command higher priority for the same fee or tip, or hold the same priority for less. And clawing ~10% of compute back into every block raises the ceiling on how much the network can do before blocks fill. If your edge depends on landing transactions during congestion, both of those are worth re-tuning around.
And for everyone: the most-used program on the chain is now one of the smallest, fastest, most-scrutinized things on it. That's a good direction for the whole stack you're building on.
The Quiet Upgrade
The flashy Solana upgrades get the headlines: Firedancer, new consensus, bigger blocks. p-token got almost none of that, and it may end up mattering more day-to-day than any of them, precisely because it touches the one program everything else routes through. It didn't add a feature. It took the single most common thing the network does, made it about 60x cheaper, and slid the new engine in under the old one's address without asking anyone to change a line.
That's the kind of upgrade you only notice if you go looking at the compute meter. Which, if your business runs on Solana, is exactly where you should be looking.
OrbitFlare builds the infrastructure under Solana apps: RPC, WebSocket, Yellowstone gRPC, Jetstream shred-decoded streaming, and Shredstream.
Resources
p-token: How Solana Rewrote Its Most Important Program
Related articles
Top 10 Solana RPC Providers in 2026
Ranked breakdown of the ten Solana RPC providers worth considering in 2026, with a benchmarking checklist and a use-case-to-vendor map.
FundamentalsBefore the Block, There's the Shred
Every transaction on Solana is broken into 1,228-byte fragments called shreds before it reaches a single validator. They travel through a stake-weighted tree, and whoever sees them first has the edge.
FundamentalsThe Two BPFs: How a Packet Filter Runs Code on Your Favourite Blockchain
Your Solana programs compile to the same bytecode that secures kernels at Netflix, Cloudflare, and Facebook. Two forks of one VM - one observes the system, the other is the system.