Dual-Stream Solana Indexer
Sourav Mishra
Apr 2, 2026 • 21 min read



Building a Dual-Stream Solana Indexer with gRPC
Every Solana project eventually hits the same wall. You need historical transaction data, you need it filtered, and you need it queryable. The usual path is hammering RPC endpoints with getSignaturesForAddress and getTransaction in a loop, paging through results, parsing responses, handling rate limits, and storing everything yourself. It works. It also falls apart the moment you need real-time data alongside historical queries, or when the volume of transactions you care about goes from dozens per minute to thousands per second.
The alternative is streaming. Open a gRPC connection, tell the server which accounts or programs you care about, and receive matching transactions as they land on-chain. No polling, no rate limits, no wasted bandwidth on transactions you immediately discard.
This project takes that a step further. Instead of one stream, it runs two simultaneously - Jetstream and Yellowstone - writing both into the same PostgreSQL database and automatically merging the results. The fast stream gives you speed. The complete stream gives you depth. The database gives you both at once.
Why Two Streams
This is the obvious first question, and the answer comes down to what each source actually provides.
Jetstream is OrbitFlare's gRPC streaming service, built on top of decoded shreds. Instead of waiting for a validator to assemble a full block and serialize it through Geyser, Jetstream decodes raw Turbine shreds and streams the transaction data out as soon as it's available. That's why it's fast - it's reading from the lowest layer of Solana's data propagation. The tradeoff is that shred-level data gives you the essentials: signature, slot, account keys, instruction count. It doesn't include fees, log messages, inner instructions (CPIs), or error details, because those come from the validator's execution layer, not the shreds themselves.
Yellowstone is the Geyser-compatible gRPC interface exposed by Solana validators. It's the complete picture: full transaction metadata, fees, success/failure status, log messages, and every CPI (cross-program invocation) the transaction triggered. The tradeoff is that it's slower to deliver, because the validator has to finish processing the block, execute all the programs, and serialize the results before anything reaches Geyser.
Neither stream alone gives you everything. Jetstream is fast but shallow. Yellowstone is deep but slower. Running both means Jetstream writes the row first (because it arrives first), and when Yellowstone delivers the same transaction a moment later, the database enriches that row with fees, logs, CPIs, and the actual success/failure result.
The source column in the database tracks this: jetstream if only Jetstream has written it, yellowstone if only Yellowstone, and both once the second source fills in the gaps.
Architecture
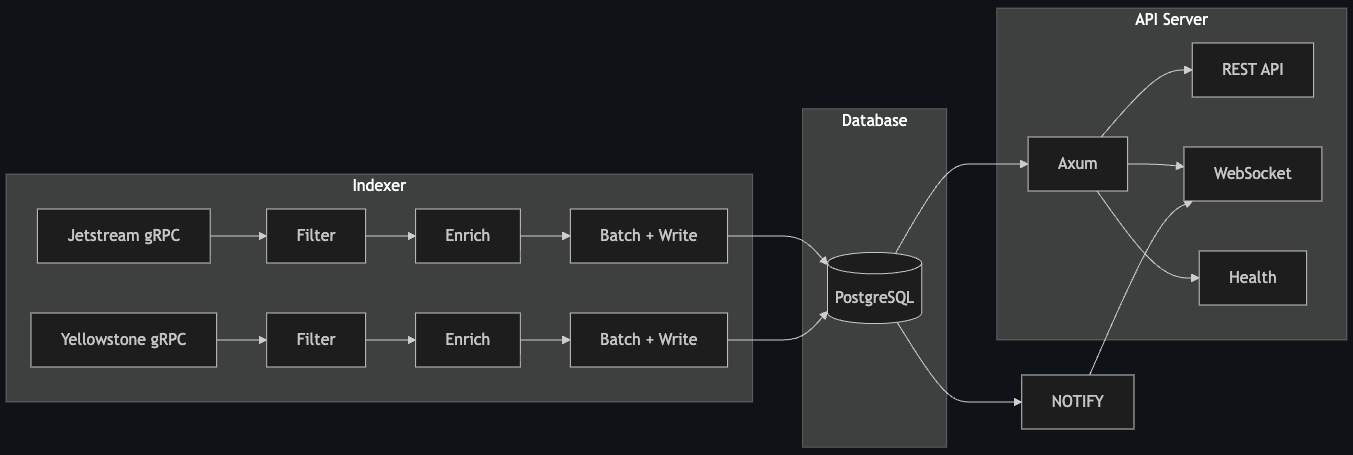
The indexer is split into modular crates, each with a single job:
- proto - Compiles
.protofiles into Rust types at build time - core - Defines traits. No implementations, just interfaces
- config - Loads YAML configuration and environment variables
- ingest - Jetstream and Yellowstone gRPC clients
- filter - Local transaction filtering
- db - PostgreSQL sink with upsert logic, query layer, SeaORM entities
- indexer - Main binary. Wires everything together, runs the pipeline
- server - Separate binary. REST API + WebSocket live feed
- frontend - Optional Next.js explorer + dashboard on top of the API
Every major boundary is a trait. The pipeline doesn't know or care whether it's reading from Jetstream, Yellowstone, or some future third source. It calls .connect(), .next(), and .reconnect(). Same for filtering, enrichment, and storage. Swap the implementation, the pipeline doesn't change.
Core Traits
The entire system hangs on four traits defined in the core crate:
#[async_trait]
pub trait TransactionStream: Send + Sync {
async fn connect(&mut self) -> Result<()>;
async fn next(&mut self) -> Result<Option<RawTransaction>>;
async fn reconnect(&mut self) -> Result<()>;
fn source(&self) -> StreamSource;
}
pub trait TransactionFilter: Send + Sync {
fn filter(&self, tx: &RawTransaction) -> bool;
fn name(&self) -> &str;
}
#[async_trait]
pub trait TransactionEnricher: Send + Sync {
async fn enrich(&self, tx: RawTransaction) -> Result<ProcessedTransaction>;
fn name(&self) -> &str;
}
#[async_trait]
pub trait TransactionSink: Send + Sync {
async fn write(&self, tx: &ProcessedTransaction) -> Result<()>;
async fn write_batch(&self, txs: &[ProcessedTransaction]) -> Result<()>;
async fn flush(&self) -> Result<()>;
fn name(&self) -> &str;
}This isn't abstraction for the sake of abstraction. It means you can write an ElasticsearchSink or a ClickHouseSink and drop it in without touching the pipeline code. Same with filters - the CompositeFilter chains them together with AND logic, and adding a new filter is one struct and one trait impl.
Project Setup
Install the OrbitFlare CLI and scaffold the project:
cargo install orbitflare
orbitflare template --install orbit-grpc-indexer
cd orbit-grpc-indexerThis gives you the full workspace, config files, migrations, proto definitions, and an optional frontend. You'll also need a PostgreSQL instance - the included Docker Compose file handles that:
docker compose up -dCopy the environment template and fill in your endpoints:
cp .env.example .envJETSTREAM_URL=http://jp.jetstream.orbitflare.com
YELLOWSTONE_URL=http://fra.rpc.orbitflare.com:10000
DATABASE_URL=postgres://indexer:indexer@localhost:5432/jetstream_indexerGet your Jetstream and Yellowstone endpoints configured by signing up at OrbitFlare.
Configuration
Everything tunable lives in config.yml. The config controls both gRPC sources, database behavior, local filters, batch settings, and logging:
jetstream:
timeout_secs: 30
tcp_keepalive_secs: 60
enabled: true
reconnect:
base_delay_ms: 1000
max_delay_ms: 30000
multiplier: 2.0
max_retries: 0
transactions:
account_include: []
account_exclude: []
account_required: []
yellowstone:
timeout_secs: 30
tcp_keepalive_secs: 60
enabled: true
commitment: "confirmed"
reconnect:
base_delay_ms: 1000
max_delay_ms: 30000
multiplier: 2.0
max_retries: 0
transactions:
vote: false
failed: null
account_include: []
account_exclude: []
account_required:
- "6EF8rrecthR5Dkzon8Nwu78hRvfCKubJ14M5uBEwF6P"
database:
max_connections: 10
min_connections: 2
run_migrations: true
filters:
program_ids: []
accounts: []
require_success: false
batching:
size: 100
flush_interval_ms: 500
retry_count: 3
retry_delay_ms: 1000max_retries: 0 means infinite retries on disconnect. The batching section controls how transactions are grouped before writing to the database - either 100 transactions accumulate or 500ms passes, whichever comes first. You can also enable or disable either stream independently. If you only want Jetstream, set yellowstone.enabled: false. The pipeline adapts.
Connecting to Jetstream
The Jetstream client opens a gRPC channel with TCP keepalive, builds a subscription request from your config, and starts receiving:
async fn create_channel(&self, url: &str) -> Result<Channel> {
Channel::from_shared(url.to_string())
.map_err(|e| IndexerError::Connection(format!("invalid endpoint: {e}")))?
.timeout(Duration::from_secs(self.config.timeout_secs))
.tcp_keepalive(Some(Duration::from_secs(self.config.tcp_keepalive_secs)))
.connect_timeout(Duration::from_secs(self.config.timeout_secs))
.connect()
.await
.map_err(|e| IndexerError::Connection(format!("jetstream connect failed: {e}")))
}
async fn establish_stream(&self) -> Result<GrpcStream> {
let channel = self.create_channel(&self.url).await?;
let mut client = JetstreamClient::new(channel);
let request = self.build_subscribe_request();
let outbound = tokio_stream::iter(vec![request]);
let response = client
.subscribe(outbound)
.await
.map_err(|e| IndexerError::Stream(format!("jetstream subscribe failed: {e}")))?;
Ok(response.into_inner())
}The subscription is bidirectional - you send filter requests, Jetstream responds with a stream of updates. Each update is either a transaction, a ping, or a pong. Transactions get parsed into the shared RawTransaction type:
fn parse_transaction(
tx_info: SubscribeUpdateTransactionInfo,
slot: u64,
) -> RawTransaction {
let signature = bs58::encode(&tx_info.signature).into_string();
let account_keys: Vec<String> = tx_info
.account_keys
.iter()
.filter(|k| k.len() == 32)
.map(|k| bs58::encode(k).into_string())
.collect();
RawTransaction {
signature,
slot,
block_time: None,
fee: None,
success: true,
err: None,
num_instructions: tx_info.instructions.len() as u32,
account_keys,
log_messages: vec![],
inner_instructions: vec![],
raw: None,
source: StreamSource::Jetstream,
}
}Notice the missing fields: fee is None, log_messages and inner_instructions are empty. Jetstream doesn't have this data.
Connecting to Yellowstone
The Yellowstone client follows the same pattern but produces a much richer RawTransaction. It connects to OrbitFlare's Yellowstone gRPC and parses the full transaction metadata:
fn parse_transaction(
tx_info: SubscribeUpdateTransactionInfo,
slot: u64,
) -> Option<RawTransaction> {
let signature = bs58::encode(&tx_info.signature).into_string();
let meta = tx_info.meta.as_ref();
let transaction = tx_info.transaction.as_ref()?;
let message = transaction.message.as_ref()?;
let account_keys: Vec<String> = message
.account_keys
.iter()
.filter(|k| k.len() == 32)
.map(|k| bs58::encode(k).into_string())
.collect();
let fee = meta.map(|m| m.fee);
let success = meta
.map(|m| m.err.is_none() || m.err.as_ref().is_some_and(|e| e.err.is_empty()))
.unwrap_or(true);
let log_messages = meta
.map(|m| m.log_messages.clone())
.unwrap_or_default();
// Parse inner instructions (CPIs)
let inner_instructions = meta
.map(|m| {
m.inner_instructions
.iter()
.flat_map(|ii| {
let idx = ii.index;
ii.instructions.iter().map(move |instr| {
InnerInstruction {
instruction_index: idx,
depth: instr.stack_height.unwrap_or(1),
program_id: keys.get(instr.program_id_index as usize)
.cloned().unwrap_or_default(),
accounts: instr.accounts.iter()
.filter_map(|&i| keys.get(i as usize).cloned())
.collect(),
data: bs58::encode(&instr.data).into_string(),
}
})
})
.collect()
})
.unwrap_or_default();
Some(RawTransaction {
signature,
slot,
fee,
success,
log_messages,
inner_instructions,
source: StreamSource::Yellowstone,
..
})
}Yellowstone also tracks the last slot it received. On restart, it queries the database for MAX(slot) and passes that as from_slot in the subscription request, so it resumes from where it left off instead of starting from the current tip. No gaps in your data.
The Pipeline
Both streams feed into the same pipeline. Each stream gets its own tokio task, its own filter, its own enricher, and its own sink instance. They run fully independently and write to the same database in parallel.
The pipeline does three things in a loop: receive a transaction, filter and enrich it, then batch it for writing.
loop {
tokio::select! {
_ = shutdown_rx.changed() => {
// Flush remaining batch and exit
if !batch.is_empty() {
sink.write_batch(&batch).await;
}
break;
}
_ = flush_timer.tick() => {
// Time-based flush: don't let transactions sit in the batch too long
if !batch.is_empty() {
sink.write_batch(&batch).await;
batch.clear();
}
}
result = stream.next() => {
match result {
Ok(Some(raw_tx)) => {
if !filter.filter(&raw_tx) {
metrics.total_filtered.fetch_add(1, Ordering::Relaxed);
continue;
}
let processed = enricher.enrich(raw_tx).await?;
// Broadcast to WebSocket clients
let _ = tx_broadcast.send(serde_json::to_string(&json!({
"signature": &processed.signature,
"slot": processed.slot,
"source": processed.source.to_string(),
})));
batch.push(processed);
if batch.len() >= batch_config.size {
sink.write_batch(&batch).await;
batch.clear();
}
}
Err(e) => {
// Flush, then reconnect
stream.reconnect().await;
}
_ => continue,
}
}
}
}The tokio::select! macro is doing the heavy lifting here. It waits on three things simultaneously: a shutdown signal, a flush timer, or the next transaction from the stream. Whichever fires first gets handled, and the loop continues.
Batching matters because writing one transaction at a time to PostgreSQL is painfully slow at high throughput. Grouping 100 transactions per write (or flushing every 500ms for lower-volume streams) keeps database round-trips manageable.
On stream errors, the pipeline flushes whatever it has in the batch, then attempts a reconnect with exponential backoff: 1 second, 2 seconds, 4 seconds, up to a 30-second cap. If the connection comes back, the pipeline picks up where it left off.
The Merge Strategy
This is the part that ties the two streams together. When a transaction arrives, the PostgreSQL sink runs an upsert:
INSERT INTO transactions (
signature, slot, block_time, fee, success, err,
num_instructions, accounts, log_messages,
has_cpi_data, source, raw, indexed_at
) VALUES ($1, $2, $3, $4, $5, $6, $7, $8, $9, $10, $11, $12, $13)
ON CONFLICT (signature) DO UPDATE SET
fee = COALESCE(EXCLUDED.fee, transactions.fee),
success = EXCLUDED.success,
err = COALESCE(EXCLUDED.err, transactions.err),
log_messages = CASE
WHEN array_length(EXCLUDED.log_messages, 1) IS NOT NULL
THEN EXCLUDED.log_messages
ELSE transactions.log_messages
END,
has_cpi_data = transactions.has_cpi_data OR EXCLUDED.has_cpi_data,
source = CASE
WHEN transactions.source != EXCLUDED.source THEN 'both'
ELSE EXCLUDED.source
END,
enriched_at = CASE
WHEN EXCLUDED.has_cpi_data AND NOT transactions.has_cpi_data
THEN NOW()
ELSE transactions.enriched_at
ENDWalk through what happens with a real transaction. Jetstream delivers it first. The row gets inserted with fee = NULL, success = true (optimistic), empty log messages, source = 'jetstream'. A moment later, Yellowstone delivers the same transaction. The ON CONFLICT fires, and each column gets resolved individually:
- fee:
COALESCEpicks Yellowstone's value since Jetstream wrote NULL - success: Overwritten with the actual result from Yellowstone
- err:
COALESCEfills in error details if the transaction failed - log_messages: Replaced if Yellowstone provides non-empty logs
- has_cpi_data: OR operation, so once it's true, it stays true
- source: Flips to
'both'since the existing source differs from the incoming one - enriched_at: Set to
NOW()when Yellowstone first enriches a Jetstream-only row
Inner instructions (CPIs) go into their own table, keyed by signature, with ON CONFLICT DO NOTHING since only Yellowstone provides them. A third table, accounts_touched, denormalizes account lookups for fast queries by address.
After every write, the sink sends a NOTIFY new_transaction through PostgreSQL's built-in pub/sub. This is how the API server's WebSocket feed gets its data without polling.
Filtering
Filters run locally after the gRPC server has already done its server-side filtering. This second layer catches anything the server-side filters can't express, or applies logic specific to your use case.
The CompositeFilter chains multiple filters together with AND logic:
pub struct CompositeFilter {
filters: Vec<Box<dyn TransactionFilter>>,
}
impl CompositeFilter {
pub fn from_config(config: &FilterConfig) -> Self {
let mut filters: Vec<Box<dyn TransactionFilter>> = Vec::new();
if !config.program_ids.is_empty() {
filters.push(Box::new(ProgramFilter::new(config.program_ids.clone())));
}
if !config.accounts.is_empty() {
filters.push(Box::new(AccountFilter::new(config.accounts.clone())));
}
if config.require_success {
filters.push(Box::new(SuccessFilter));
}
Self::new(filters)
}
}
impl TransactionFilter for CompositeFilter {
fn filter(&self, tx: &RawTransaction) -> bool {
self.filters.iter().all(|f| f.filter(tx))
}
}If the filters list is empty, everything passes through. Adding your own filter means implementing one method on one trait and registering it in the composite.
The Database Schema
Three tables, seven indexes:
CREATE TABLE transactions (
signature TEXT PRIMARY KEY,
slot BIGINT NOT NULL,
block_time TIMESTAMPTZ,
fee BIGINT,
success BOOLEAN NOT NULL,
err JSONB,
num_instructions INTEGER,
accounts TEXT[] NOT NULL DEFAULT '{}',
log_messages TEXT[] NOT NULL DEFAULT '{}',
has_cpi_data BOOLEAN NOT NULL DEFAULT FALSE,
source TEXT NOT NULL,
raw JSONB,
indexed_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
enriched_at TIMESTAMPTZ
);
CREATE INDEX idx_tx_slot ON transactions(slot);
CREATE INDEX idx_tx_block_time ON transactions(block_time);
CREATE INDEX idx_tx_success ON transactions(success);
CREATE INDEX idx_tx_source ON transactions(source);
CREATE INDEX idx_tx_accounts ON transactions USING GIN(accounts);The GIN index on the accounts array column is what makes "find all transactions involving this address" fast. Without it, every query would scan the entire table checking if the address exists in each row's account list.
Migrations run automatically on startup when database.run_migrations is set to true.
The API Server
The API server is a separate binary that reads from the same database and exposes the indexed data through REST endpoints and a WebSocket live feed:
GET /health
GET /api/v1/transactions
GET /api/v1/transactions/{signature}
GET /api/v1/accounts/{address}/transactions
WS /ws/transactionsIt supports both cursor-based and offset-based pagination, plus filters for source, success status, and slot range:
GET /api/v1/transactions?limit=25&source=both&success=true
GET /api/v1/transactions?pagination=offset&offset=0&limit=50
GET /api/v1/accounts/6EF8rrecthR5Dkzon8Nwu78hRvfCKubJ14M5uBEwF6P/transactionsFetching a specific transaction by signature returns the full record including any inner instructions (CPIs) from the joined table.
The WebSocket endpoint is where the live feed comes in. The API server listens for PostgreSQL NOTIFY events using PgListener and broadcasts them to connected WebSocket clients:
fn spawn_pg_listener(database_url: &str, tx: broadcast::Sender<String>) {
tokio::spawn(async move {
loop {
match PgListener::connect(&url).await {
Ok(mut listener) => {
listener.listen("new_transaction").await?;
loop {
match listener.recv().await {
Ok(notification) => {
let _ = tx.send(notification.payload().to_string());
}
Err(_) => break, // reconnect on error
}
}
}
Err(_) => tokio::time::sleep(Duration::from_secs(1)).await,
}
}
});
}No polling. The indexer writes a transaction, fires a NOTIFY, PostgreSQL delivers it to the API server, and the API server pushes it to every connected WebSocket client. The latency from database write to WebSocket delivery is effectively zero.
Building and Running
Build both binaries in release mode:
cargo build --releaseStart the indexer:
./target/release/orbit-grpc-indexerIn a separate terminal, start the API server:
./target/release/indexer-api-serverThe indexer connects to both gRPC sources and starts writing to PostgreSQL. The API server binds to port 3000 (configurable via the PORT environment variable) and starts serving requests immediately.
Metrics are logged every 30 seconds:
INFO jetstream_rx=4821 yellowstone_rx=3094 indexed=7891 filtered=24 errors=0 metricsExtending It
The trait-based architecture means you can swap or extend any layer without rewriting the pipeline.
Custom sinks. Want to write to Elasticsearch instead of Postgres? Implement TransactionSink and pass it to Pipeline::spawn_stream. The pipeline doesn't care what's on the other end.
Custom filters. Need to filter by instruction data, fee amount, or some application-specific logic? Implement TransactionFilter, add it to the composite, done.
Custom enrichment. The default enricher just flags whether CPI data is present. You could write one that decodes specific program instructions, calculates token amounts, or tags transactions with custom metadata before they hit the database.
Additional streams. The TransactionStream trait doesn't assume gRPC. You could implement it over WebSocket, HTTP polling, or reading from a file. The pipeline treats every source the same way.
Frontend. The template includes an optional Next.js dashboard in the frontend/ directory if you want a visual interface on top of the API.
When You Need This
If you're building something that needs to query Solana transaction history by account, program, or time range, and you need that data to be up-to-date within seconds, this is the template to start from. Analytics dashboards, compliance tools, DEX aggregators, wallet activity feeds, protocol monitors - these all need the same core capability: ingest, store, query.
Fetching this data on demand from RPC works fine for small-scale use cases. But the moment you need it consistently, at volume, with low latency and the ability to query across multiple dimensions, you need your own index. This gets you there.
Resources
Dual-Stream Solana Indexer
Related articles
Building a Real-Time Solana Wallet Tracker
Tired of chasing Solana transactions and always being behind? Fret no more. Let's build a wallet tracker using OrbitFlare's Jetstream that filters and streams transactions in real-time, decodes PumpFun trades and fires alerts based on activity that you add in the config.
DevelopersPrepare your apps for Agave v2.0 upgrade
The Agave 2.0 validator client brings significant updates including breaking changes, API endpoint removals and Rust crate renamings.